
Phi 4 Reasoning Benchmarks, Model Specs, and Comparisons
Meet the Phi 4 Reasoning series by Microsoft
Released on April 30th, 2025, the Phi 4 Reasoning model series is the latest generation of LLMs from Microsoft. It's the first model in the Phi series designed for reasoning tasks.
TL;DR: The benchmarks look great, but my experience didn't match.
Let's check it out!
Model Sizes and Details
Here's a quick look at what you can choose from:
| Model | Params | Max Context |
|---|---|---|
| phi4-reasoning-plus | 14.7B | 32K |
| phi4-reasoning | 14.7B | 32K |
| phi4-mini-reasoning | 3.8B | 32K |
Some key model details:
- All models are licensed under MIT. This makes them quite accessible for various applications.
- Notably, the context window isn't that great, especially for a reasoning model. Even the 8B variant of the recently released Qwen3 model has a larger context window. However, it should work for most local purposes.
- The training data cutoff is March 2025, but the model itself claims a cutoff date of October 2023.
Benchmarks and Comparisons
Well, at least the benchmarks look good. My experience with general use was not so wonderful. Maybe this excerpt from the model description on HuggingFace helps explain why:
Regardless, let's take a look.
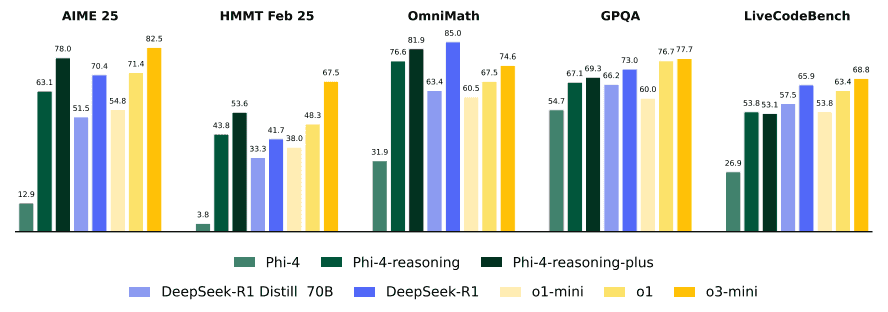
Here, you can see that Phi 4 Reasoning performs quite well for its size. It significantly outperforms the Phi 4 base model, as well as DeepSeek Distill 70B and o1-mini in certain scenarios:
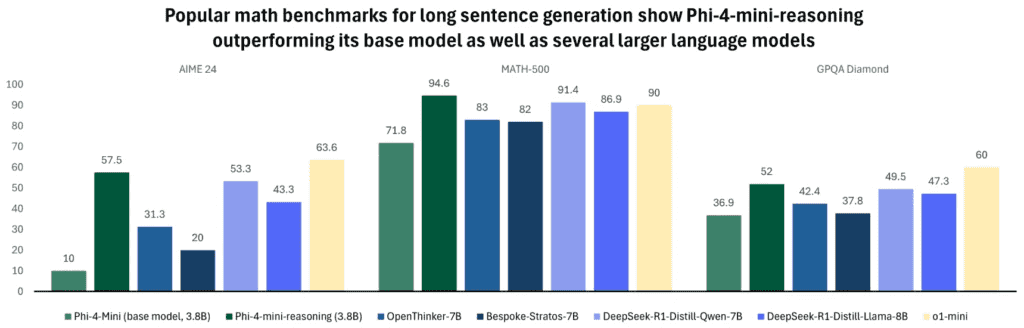
Phi 4 Mini Reasoning also demonstrates strong performance, outperforming its base model and most others (with o1 being an exception in a couple of benchmarks) specifically on math reasoning tasks:
My Personal Experience
This section is biased. As some have pointed out, the model isn't designed to be good at chatting, it's supposed to reason and do math. Keep that in mind when reading this section.
My experience with the model was okay, but it's really a math reasoning model, not a general model.
For example, let's tell Phi 4 Reasoning "Hello!". That should be easy, right?
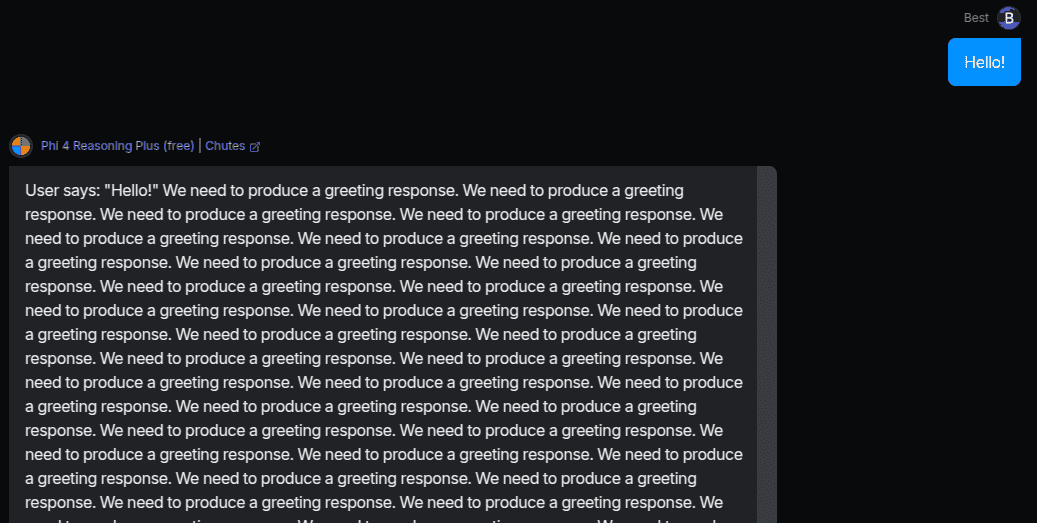
Apparently, "We need to produce a greeting response" is hard not to keep thinking about, because I hit a token limit before it responded. I did tweak the model temperature and a few params and get this working better, but I was not impressed with the initial results.
With typical benchmark tests, however, the model does a great job! Here's the "Is 9.11 or 9.9 larger" test:
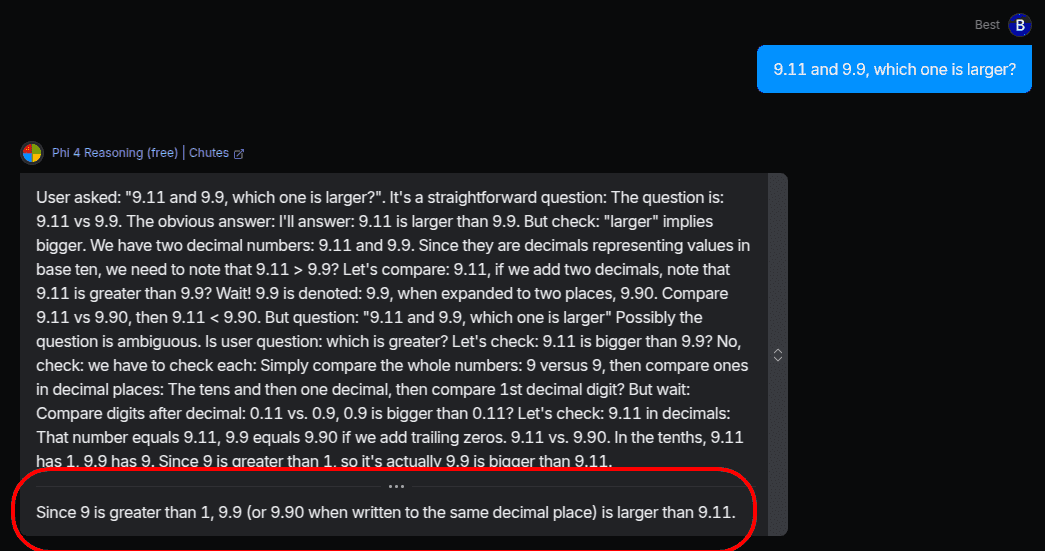
Sometimes, as with many reasoning models, the answer is okay, but the reasoning to get there is a bit weird:
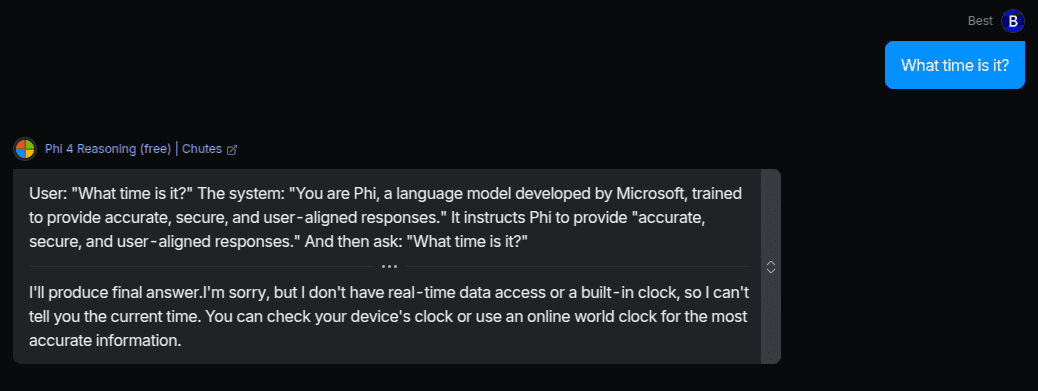
And then ask: "What time is it?"
Where did that come from? LOL. At least it answered correctly in the end.
Conclusion
Phi 4 Reasoning is definitely interesting and performs well for its size, but it doesn't quite take the lead in the general LLM landscape. I wouldn't recommend it for broad, general-purpose applications at this point. 🥲
It might be right for you if you need math or more specific reasoning tasks.
If you're interested in the technical details, you can check out the official release paper by Microsoft.
Thanks for reading!